
このサイトを参照しながら、映画データのグラフ化の学習をする。
%download https://raw.githubusercontent.com/aysbt/Data_Cleaning/master/data/tmdb_movies_data.csv
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
df = pd.read_csv('tmdb_movies_data.csv')
df.head(3)
重複データを検出して、検出された行を削除する。
sum(df.duplicated())
df.drop_duplicates(inplace=True)
公開日のフォーマットをDatetimeフォーマットに変える。
df['release_date'] = pd.to_datetime(df['release_date'])
df['release_date'].head()
#制作費と興行収入の0をNANに変える。
df[['budget','revenue']] = df[['budget','revenue']].replace(0,np.NAN)
df.dropna(subset=['budget', 'revenue'], inplace=True)
print('After cleaning, we have {} rows'.format(df.shape[0]))
#必要ない列を削除する
del_col = ['imdb_id','homepage','tagline','keywords','budget_adj','revenue_adj']
df.drop(del_col, axis=1, inplace=True)
print('We have {} rows and {} columns' .format(df.shape[0], df.shape[1]))
#興行収入から制作費を引いて映画毎の粗利益を求める。
df['profit'] = df['revenue']-df['budget']
df['profit'] = df['profit'].apply(np.int64)
df['budget'] = df['budget'].apply(np.int64)
df['revenue'] = df['revenue'].apply(np.int64)
スポンサーリンク
各種関数を設定する¶
def find_min_max(col_name):
#idxmin()とidxmax()関数を使って所与列の最小・最大値を検出する。
min_index = df[col_name].idxmin()
max_index = df[col_name].idxmax()
#所与col_nameから最小・最大値を選択する。
low = pd.DataFrame(df.loc[min_index,:])
high = pd.DataFrame(df.loc[max_index,:])
print('Movie which has highest '+col_name+' : ', df['original_title'][max_index])
print('Movie which has lowest '+col_name+' : ', df['original_title'][min_index])
return pd.concat([high,low], axis=1)
def top_10(col_name,size=10):
#所与列の歴代トップ10を検出する。
#所与列をソートしてトップ10を選択する。
df_sorted = pd.DataFrame(df[col_name].sort_values(ascending=False))[:size]
df_sorted['original_title'] = df['original_title']
plt.figure(figsize=(20,14))
plt.rc('xtick', labelsize=25)
plt.rc('ytick', labelsize=25)
#平均を算出する。
avg = np.mean(df[col_name])
sns.barplot(x=col_name, y='original_title', data=df_sorted, label=col_name)
plt.axvline(avg, color='k', linestyle='--', label='mean')
if (col_name == 'profit' or col_name == 'budget' or col_name == 'revenue'):
plt.xlabel(col_name.capitalize() + ' (U.S Dolar)',fontsize=30)
else:
plt.xlabel(col_name.capitalize())
plt.ylabel('')
plt.title('Top 10 Movies in: ' + col_name.capitalize(),fontsize=30)
plt.legend(prop={'size': 36})
from matplotlib import gridspec
def each_year_best(col_name, size=15):
#この関数は過去15年のベスト所与値をプロットする。
release = df[['release_year',col_name,'original_title']].sort_values(['release_year',col_name],
ascending=False)
#公開年でグループ化して年毎の最高利益を検出する。
release = pd.DataFrame(release.groupby(['release_year']).agg({col_name:[max,sum],
'original_title':['first'] })).tail(size)
#所与列から最大を選び出す。
x_max = release.iloc[:,0]
#所与列の合計を選び出す。
x_sum = release.iloc[:,1]
#タイトルを選ぶ。
y_title = release.iloc[:,2]
#インデックスを選ぶ
r_date = release.index
#希望の変数をプロットする。
fig = plt.figure(figsize=(20, 14))
gs = gridspec.GridSpec(1, 2, width_ratios=[2, 2])
ax0 = plt.subplot(gs[0])
ax0 = sns.barplot(x=x_max, y=y_title, palette='deep')
for j in range(len(r_date)):
#put the year information on the plot
ax0.text(j,j*1.02,r_date[j], fontsize=22, color='black')
plt.title('Last '+str(size)+' years highest '\
+col_name+' movies for each year',fontsize=20)
plt.xlabel(col_name.capitalize(),fontsize=30)
plt.ylabel('')
ax1 = plt.subplot(gs[1])
ax1 = sns.barplot(x=r_date, y=x_sum, palette='deep')
plt.xticks(rotation=90)
plt.xlabel('Release Year',fontsize=30)
plt.ylabel('Total '+col_name.capitalize(),fontsize=25)
plt.title('Last ' +str(size)+ ' years total '+ col_name,fontsize=20)
plt.tight_layout()
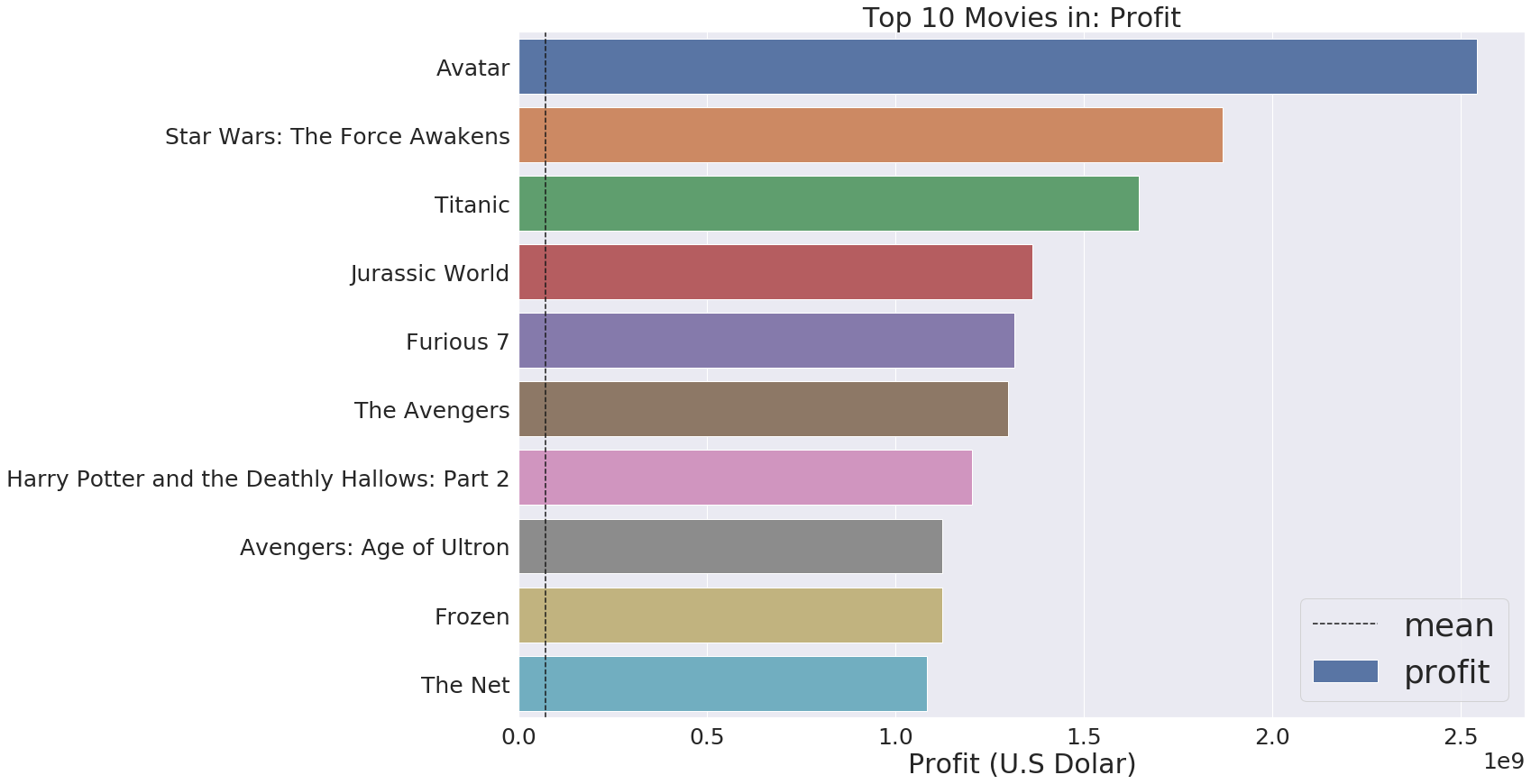
top_10('profit')
スポンサーリンク
年毎の最高興収映画と総興収をプロットする¶
each_year_best('revenue')
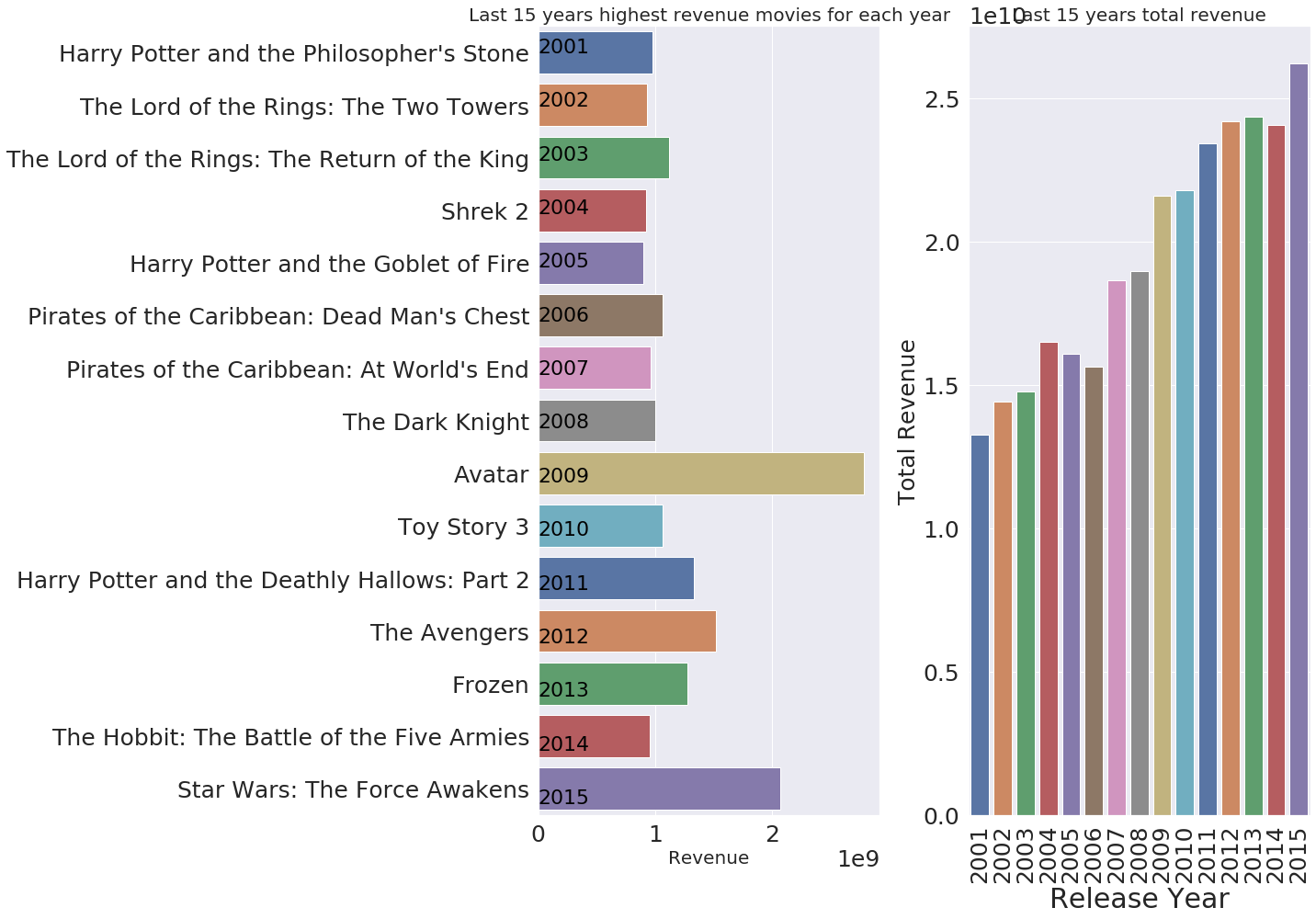
2009年のアバターが圧倒的で、総興収は2015年で250億ドルを超えている。
スポンサーリンク
過去25年間で出演最多俳優を検出する¶
def split_count_data(col_name, size=15):
#データが抽出・カウントされる必要がある列を引数として取る関数
#所与列を取ってストリング'|'によって分離する。
data = df[col_name].str.cat(sep='|')
#シリーズ中に値を個別に格納する。
data = pd.Series(data.split('|'))
#所与列の最頻出値をカウントする。
count = data.value_counts(ascending=False)
count_size = count.head(size)
#複数名のaxis名を設定する。
if (col_name == 'production_companies'):
sp = col_name.split('_')
axis_name = sp[0].capitalize()+' '+ sp[1].capitalize()
else:
axis_name = col_name.capitalize()
fig = plt.figure(figsize=(20, 16))
gs = gridspec.GridSpec(1,2, width_ratios=[2,2])
#棒グラフの所与列をカウントする。
ax0 = plt.subplot(gs[0])
count_size.plot.barh()
plt.xlabel('Number of Movies')
plt.ylabel(axis_name)
plt.title('The Most '+str(size)+' Filmed ' +axis_name+' Versus Number of Movies',fontsize=20)
ax = plt.subplot(gs[1])
#円グラフの初設定をする。
explode = []
total = 0
for i in range(size):
total = total + 0.015
explode.append(total)
#pie chart for given size and given column
ax = count_size.plot.pie(autopct='%1.2f%%', shadow=True, startangle=0, \
pctdistance=0.9,explode=explode,textprops={'fontsize': 15})
plt.title('The most '+str(size)+' Filmed ' +axis_name+ ' in Pie Chart',fontsize=20)
plt.xlabel('')
plt.ylabel('')
plt.axis('equal')
plt.legend(loc=9, bbox_to_anchor=(1.4, 1))
split_count_data('cast', size=25)
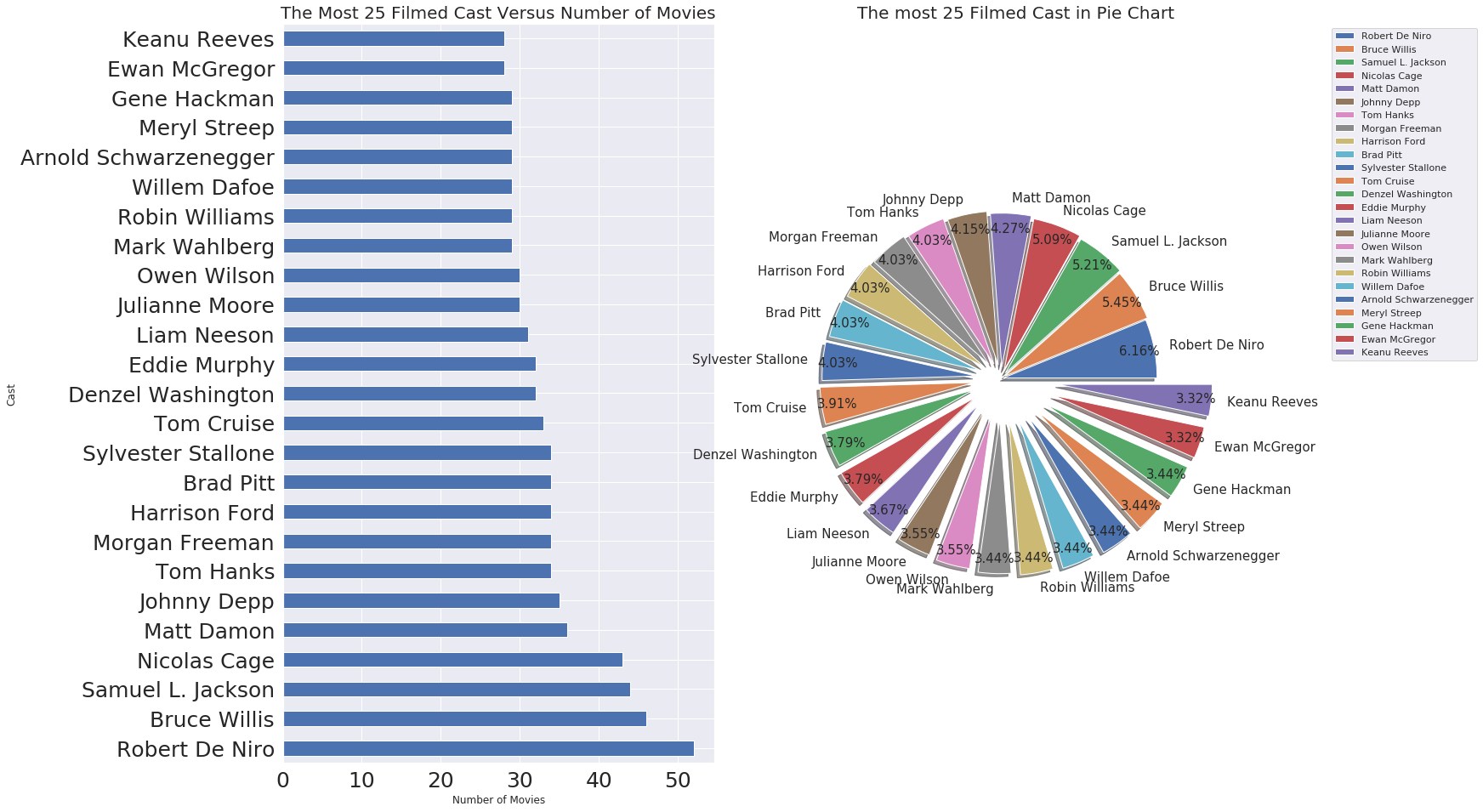
ロバートデニーロが最も出演映画が多い俳優のようである。
スポンサーリンク