
若年(0〜29歳)、中年(30〜59歳)、高年(60〜89歳)、超高年(90歳以上)の年代区分別死亡数を棒グラフで視覚化してみる。0〜34歳を若年層(35歳以上の無職者はニートとは言わない)、35〜69歳(70歳定年制とか言われている)、70歳以上の3区分でもいいかもしれない。
from pandas import *
df = read_csv('dead.csv',encoding='shift_jis')
df.head(2)
df = df.convert_objects(convert_numeric=True)
df.drop(['表章項目','死因年次推移分類','性別','/時間軸(年次)'],axis=1,inplace=True)
df.head(2)
スポンサーリンク
0〜100歳以上の年次別死亡数をプロット¶
from matplotlib.pyplot import *
from matplotlib.font_manager import FontProperties
from matplotlib import rcParams
style.use('ggplot')
fp = FontProperties(fname='/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf', size=54)
rcParams['font.family'] = fp.get_name()
rcParams["font.size"] = "20"
fig, ax = subplots(figsize=(23,17))
df[:23][1:].set_index('年齢(5歳階級)').T.plot(kind='barh',ax=ax,stacked=True)
ax.legend(loc='upper right', fancybox=True, framealpha=0.5)
xticks(np.arange(0,1.44e6,1e6/10),
['{}万'.format(int(x/1e4)) if x > 0 else 0 for x in np.arange(0,1.44e6,1e6/10)]);
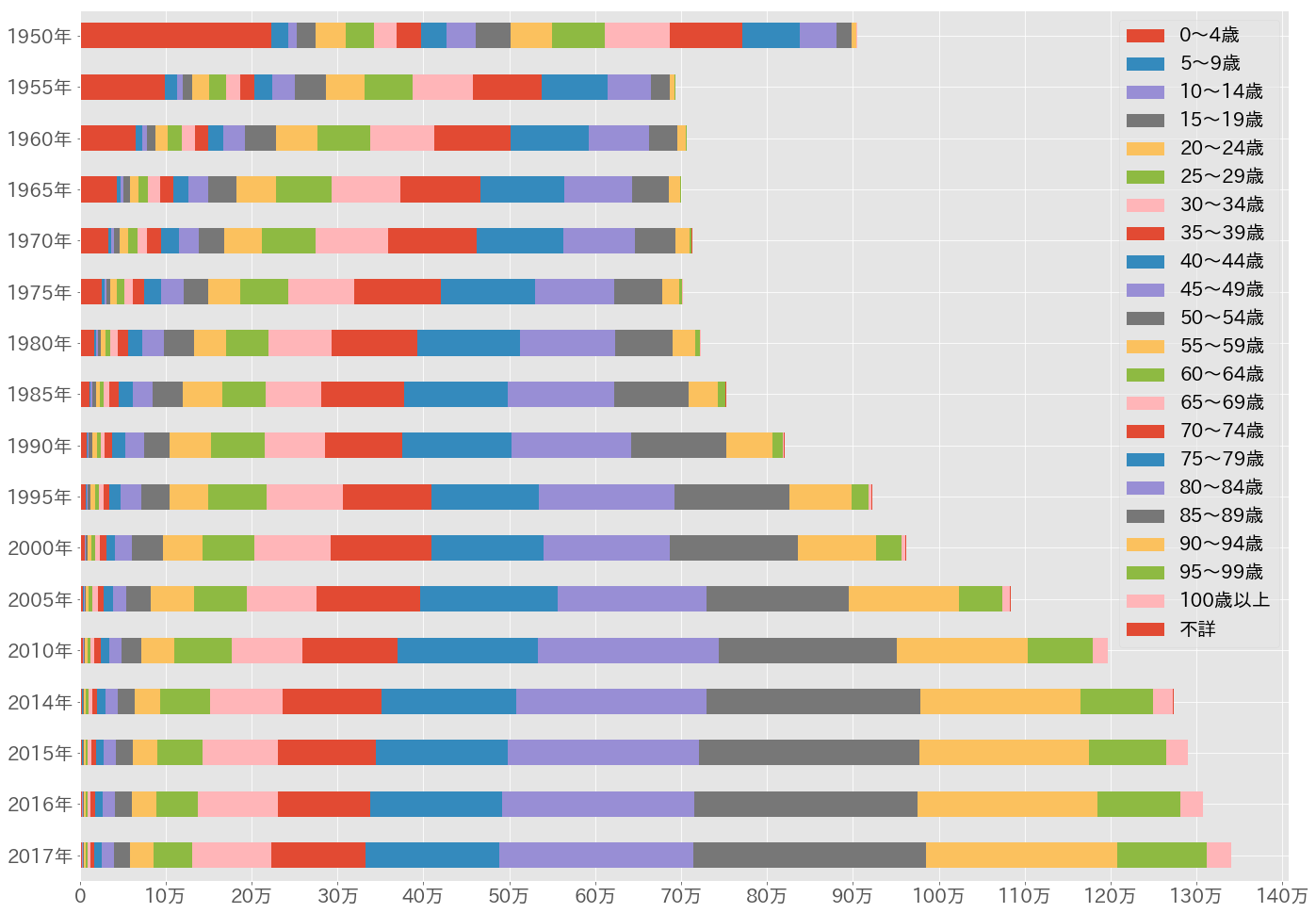
非常に醜い(見難い)グラフなので、年齢区分をもっと大雑把なものにする。
スポンサーリンク
若年・中年・高年・超高年層死亡数推移¶
年齢区分を4分割する。
df1 = df[:22][1:].groupby(np.arange(len(df[:22][1:]))//6).sum()
df1.index = df[:22][1:].loc[1::6, '年齢(5歳階級)']
df1.head(2)
インデックスの年齢区分を変更する。
df1.rename(index={'0〜4歳':'0〜29歳','30〜34歳':'30〜59歳','60〜64歳':'60〜89歳','90〜94歳':'90歳〜'},inplace=True)
df1.head(2)
インデックスをリセットする。
df1.reset_index(inplace=True)
df1.head(2)
style.use('fivethirtyeight')
fp = FontProperties(fname='/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf', size=54)
rcParams['font.family'] = fp.get_name()
rcParams["font.size"] = "20"
fig, ax = subplots(figsize=(18,10))
df1.set_index('年齢(5歳階級)').T.plot(kind='barh', ax=ax)
ax.legend(loc='upper right', fancybox=True, framealpha=0.5)
xticks(np.arange(0,9.1e5,1e5/2),
['{}万'.format(int(x/1e4)) if x > 0 else 0 for x in np.arange(0,9.1e5,1e5/2)]);
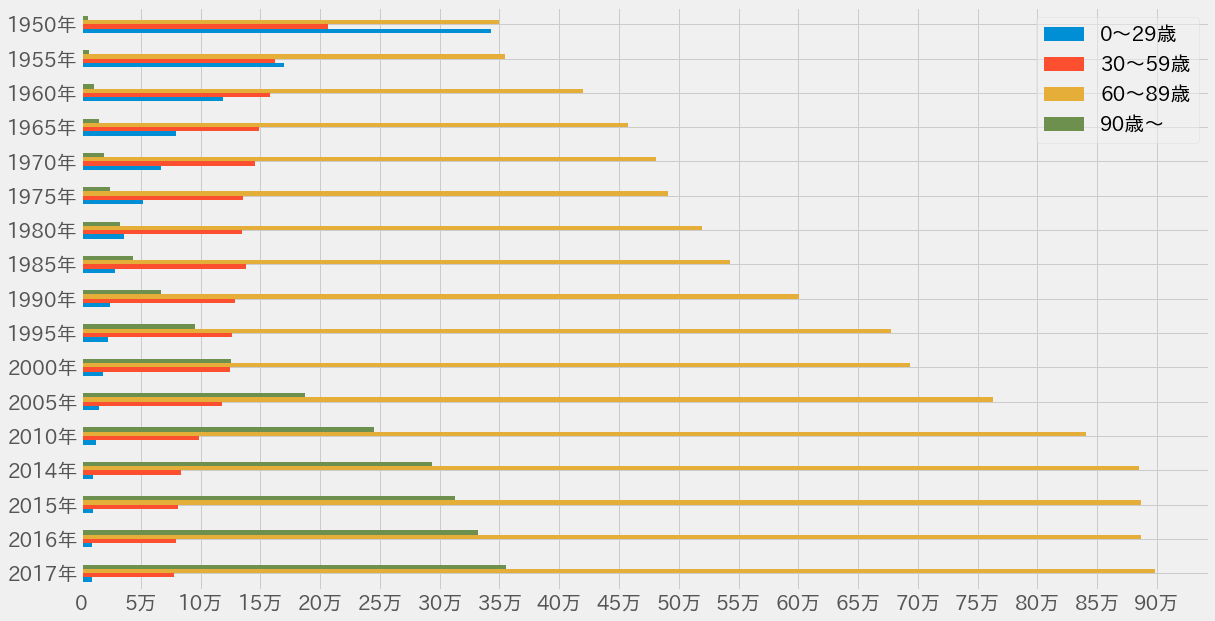
もっと見やすい棒グラフをプロットする。
style.use('seaborn-dark')
fp = FontProperties(fname='/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf', size=54)
rcParams['font.family'] = fp.get_name()
rcParams["font.size"] = "18"
fig, ax = subplots(figsize=(18,10))
df1.set_index('年齢(5歳階級)').T.plot(kind='barh',ax=ax,stacked=True)
ax.legend(loc='upper right',fancybox=True,framealpha=0.5,prop={'size': 26})
xticks(np.arange(0,1.41e6,1e6/10),
['{}万'.format(int(x/1e4)) if x > 0 else 0 for x in np.arange(0,1.41e6,1e6/10)]);
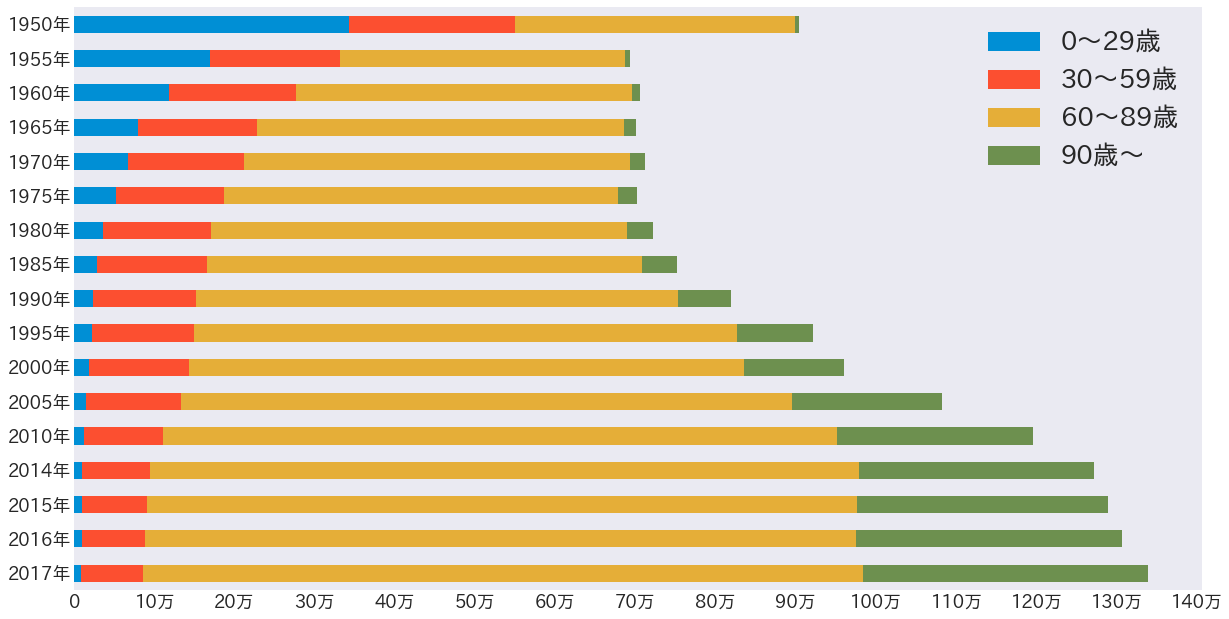
1950年は若年層が大量に死んでいる。朝鮮戦争に参戦してたかのような死にっぷりだが、実際は乳幼児が栄養失調や病気が原因で大量死している。この後、日本は朝鮮戦争特需によって奇跡の復興を遂げ、乳幼児死亡数は劇的に減少している。
スポンサーリンク