
在留資格別外国人数を国籍別に棒グラフ化してみたいと思います。日本はもっと純粋な移民と難民を受け入れるべきだという声が、昨今、国内でも高まって来ているのは良い傾向だと思われます。日本の国力を維持するためには、少なくとも、毎年30万人以上の移民を受け入れる必要があると試算されています。ただ、2012年末に203万3656人だった在留外国人数が、2018年末には273万1093人に増えているので、安倍政権の6年間で70万人近く増えた計算なので、これはこれで良い傾向ではあります。
データの下準備¶
import warnings
warnings.filterwarnings('ignore')
import tabula
df = tabula.read_pdf("http://www.moj.go.jp/content/001289225.pdf",
output_format='dataframe',
pages = '4',
encoding='utf-8',
java_options=None,
pandas_options=None,
multiple_tables=False)
df1=df.drop(['中長期在留者','Unnamed: 7'], axis=1)
df1=df1.rename(columns={'日本人の国籍・地域 計':'総数','技術・ 人文知識・':'技術・人文知識・国際業務','Unnamed: 10':'日本人の配偶者等'})
df1.head(2)
import numpy as np
df2 = df1[np.arange(len(df)) % 2 != 0]
df2
for i, col in enumerate(df2.columns):
df2.iloc[:, i] = df2.iloc[:, i].str.replace(',','').str.replace(' ','')
import re
b=[]
for i in df2['総数']:
a = re.split('(\d+)', i)
b.append(a)
m=[]
n=[]
for i,j,k in b:
m.append(i)
n.append(j)
df2['総数']=n
df2['国名']=m
cols = df2.columns.tolist()
cols = cols[-1:] + cols[:-1]
df2 = df2[cols]
import pandas as pd
df2 = df2.set_index(['国名'])
df2 = df2.apply(pd.to_numeric, errors="coerce").astype(int)
韓国をプロットする¶
from matplotlib.pyplot import *
from matplotlib.font_manager import FontProperties
from matplotlib import rcParams
style.use('fivethirtyeight')
fp = FontProperties(fname='/usr/share/fonts/opentype/ipaexfont-gothic/ipaexg.ttf', size=54)
rcParams['font.family'] = fp.get_name()
rcParams["font.size"] = "25"
fig, ax = subplots(figsize=(25,12))
rc('xtick', labelsize=35)
rc('ytick', labelsize=35)
df2.iloc[2:3:,1:11].T.sort_values(by='韓国',ascending=False).plot(ax=ax,kind='barh')
xticks(np.arange(0,3.1e5,1e5/6),
['{}万'.format(int(x/1e4)) if x > 0 else 0 for x in np.arange(0,3.1e5,1e5/6)])
ax.legend(loc='best', fancybox=True, framealpha=0.5, fontsize=40)
for i in ax.patches:
ax.text(i.get_width()+1.5e3,i.get_y()+.45,\
'{:,}人'.format(int(round((i.get_width()), 2))), fontsize=35, color='k')
ax.invert_yaxis();
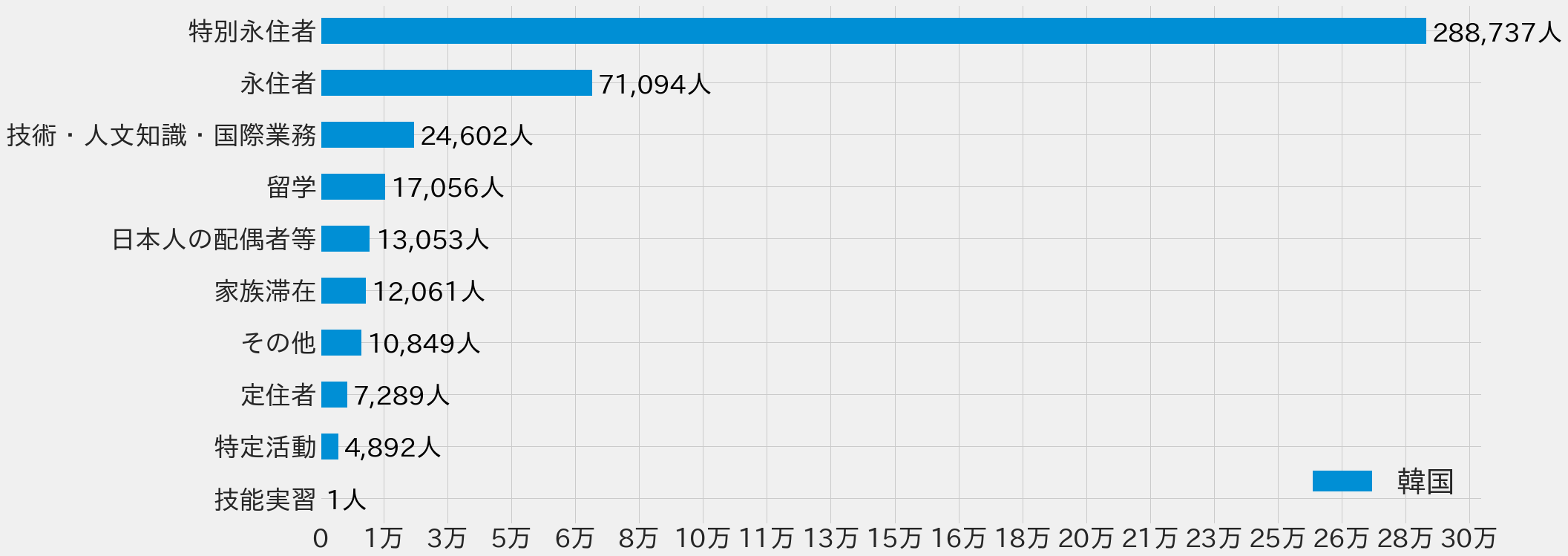
韓国人技能実習生1人って誰なんだよ!と言いたくなるのは私だけではないはずです。非常に気になります。
10カ国+その他をまとめてプロットする¶
c = cm.tab20(np.linspace(0.1, 0.9, 11))
fig, ax = subplots(figsize=(20,14))
rc('xtick', labelsize=20)
rc('ytick', labelsize=25)
df2.iloc[1:12:,1:11].T.sort_values(by='韓国',ascending=False).plot(ax=ax,kind='barh',\
color=c,stacked=True)
xticks(np.arange(0,8.1e5,1e5/2),
['{}万'.format(int(x/1e4)) if x > 0 else 0 for x in np.arange(0,8.1e5,1e5/2)])
ax.legend(loc='best', fancybox=True, framealpha=0.5, fontsize=40)
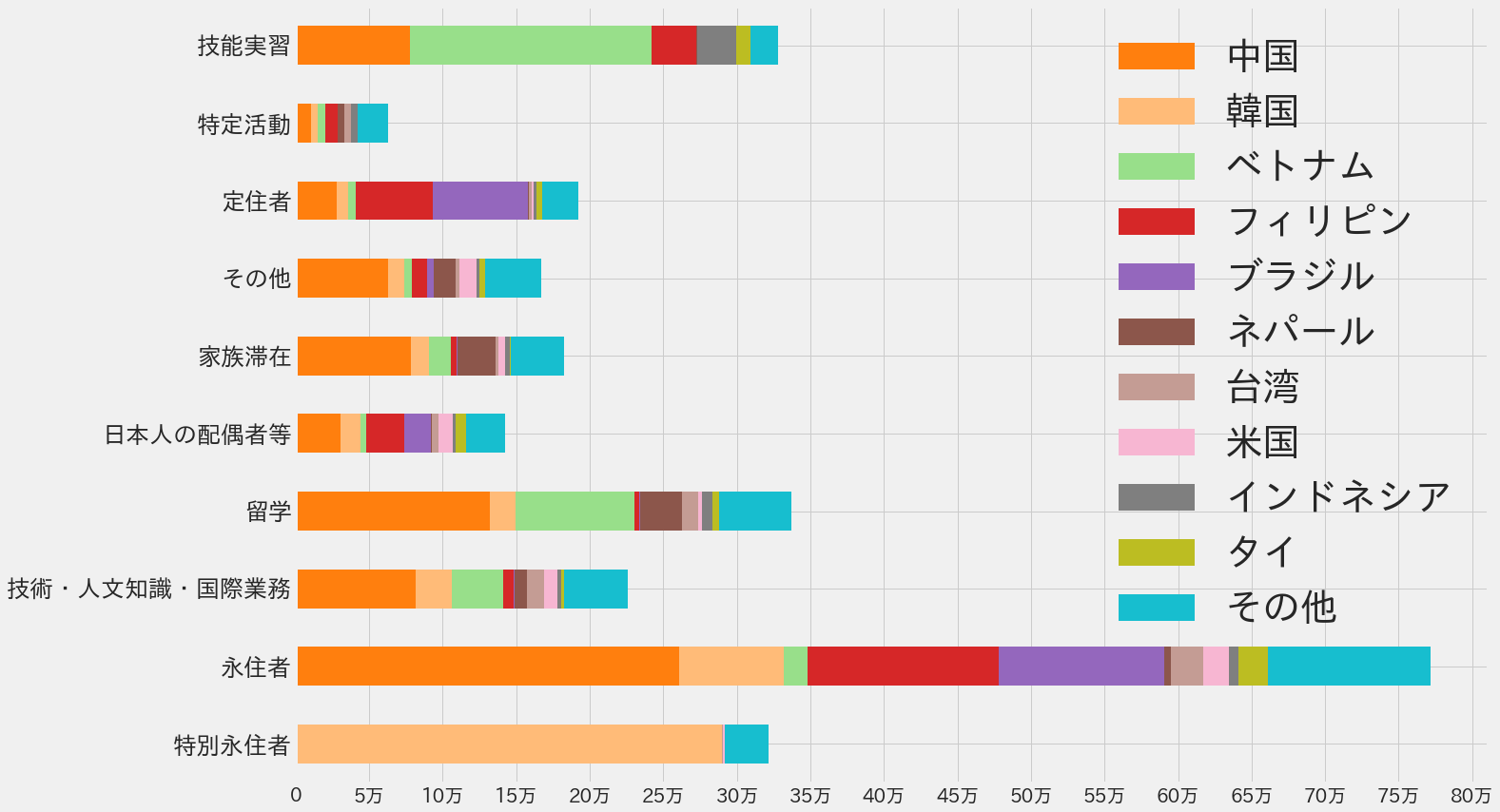
技能実習では圧倒的にベトナム人が多いことに気付かされます。永住者では、中国人を別にすれば、フィリピン人とブラジル人が多く、ベトナム人留学生も中国人に次いで多いようです。インドやパキスタン、アフガニスタンからももっと移民を受け入れた方がいいように思えます。今後のことを考えると、技能実習生と留学生はもっと欲しいところですが、日本には、中近東アフリカからもっと移民・難民を受け入れる義務があると世界中から非難されているので、この地域からもっと移民・難民を受け入れる必要があります。
1947年〜2018年の出生数と婚姻・離婚件数の推移をプロット
1950年〜2017年の日本人女性の年代別出産数推移をグラフ化
1908年〜2017年の平均婚姻年齢(初婚・全婚姻)をグラフ化
若年・中年・高年・超高年層死亡数推移(1950年〜2017年)
日本の右肩下がりの出生数と右肩上がりの死亡者数をグラフ化する
日本の交通事故死亡者数の推移を性別・年齢別に棒グラフ化する
Python:国籍別に在留外国人数の多い市町村を抽出する
Python:在留外国人の詳細を円グラフで表示する
Python:在留外国人比率の高い市町村を条件別に抽出する
Python:年齢別交通事故死亡数を死亡割合に変換する
Python:日本人の年代別・性別死亡数を視覚化して考察する
Python:日本人の年齢別死亡者数の推移をプロットして考察する
Python:1950年〜2017年の年齢別自殺数推移を棒グラフ化する
Python:結婚適齢期女性が最も余っている都市を探し出す