
今日はこのサイトを参考にして、numpy.sin, cumath.sin, ElementwiseKernel, SourceModuleの速度比較をする。numpy.sinというのは、入力値に対する三角関数の正弦を要素毎に返す関数のことらしい。
スポンサーリンク
速度比較用のコードをロード¶
import pycuda.driver as drv
import pycuda.tools
import pycuda.autoinit
import numpy
from pycuda.compiler import SourceModule
import pycuda.gpuarray as gpuarray
import pycuda.cumath
from pycuda.elementwise import ElementwiseKernel
blocks = 128
block_size = 1024
start = drv.Event()
end = drv.Event()
mod = SourceModule("""
__global__ void gpusin(float *dest, float *a, int n_iter)
{
const int i = blockDim.x*blockIdx.x + threadIdx.x;
for(int n = 0; n < n_iter; n++) {
a[i] = sin(a[i]);
}
dest[i] = a[i];
}
""")
gpusin = mod.get_function("gpusin")
kernel = ElementwiseKernel(
"float *a, int n_iter",
"for(int n = 0; n < n_iter; n++) { a[i] = sin(a[i]);}",
"gpusin")
knl = ElementwiseKernel(
"float *a",
"a[i] = sin(a[i]);",
"gpusin")
results = []
for n_iter in [10**2, 10**3, 10**4, 10**5, 10**6]:
nbr_values = blocks * block_size
#print ("Using nbr_values ==", nbr_values)
#Number of iterations for the calculations,
# 100 is very quick, 2000000 will take a while
print ("Calculating %d iterations" % (n_iter))
# create two timers so we can speed-test each approach
######################
# SourceModele SECTION
# We write the C code and the indexing and we have lots of control
# create an array of 1s
a = numpy.ones(nbr_values).astype(numpy.float32)
# create a destination array that will receive the result
dest = numpy.zeros_like(a)
start.record() # start timing
gpusin(drv.Out(dest), drv.In(a), numpy.int32(n_iter), \
grid=(blocks,1), block=(block_size,1,1) )
end.record() # end timing
# calculate the run length
end.synchronize()
sec1 = start.time_till(end)*1e-3
print ("SourceModule time and first three results:")
print ("%fs, %s" % (sec1, str(dest[:3])))
#####################
# Elementwise SECTION
# use an ElementwiseKernel with sin in a for loop all in C call from Python
a = numpy.ones(nbr_values).astype(numpy.float32)
a_gpu = gpuarray.to_gpu(a)
start.record() # start timing
kernel(a_gpu, numpy.int(n_iter))
end.record() # end timing
# calculate the run length
end.synchronize()
sec2 = start.time_till(end)*1e-3
print ("Elementwise time and first three results:")
print ("%fs, %s" % (sec2, str(a_gpu.get()[:3])))
####################################
# Elementwise Python looping SECTION
# as Elementwise but the for loop is in Python, not in C
a = numpy.ones(nbr_values).astype(numpy.float32)
a_gpu = gpuarray.to_gpu(a)
start.record() # start timing
for i in range(n_iter):
knl(a_gpu)
end.record() # end timing
# calculate the run length
end.synchronize()
sec3 = start.time_till(end)*1e-3
print ("Elementwise Python looping time and first three results:")
print ("%fs, %s" % (sec3, str(a_gpu.get()[:3])))
##################
# GPUArray SECTION
# The result is copied back to main memory on each iteration, this is a bottleneck
a = numpy.ones(nbr_values).astype(numpy.float32)
a_gpu = gpuarray.to_gpu(a)
start.record() # start timing
for i in range(n_iter):
a_gpu = pycuda.cumath.sin(a_gpu)
end.record() # end timing
# calculate the run length
end.synchronize()
sec4 = start.time_till(end)*1e-3
print ("GPUArray time and first three results:")
print ("%fs, %s" % (sec4, str(a_gpu.get()[:3])))
#############
# CPU SECTION
# use numpy the calculate the result on the CPU for reference
a = numpy.ones(nbr_values).astype(numpy.float32)
start.record() # start timing
start.synchronize()
for i in range(n_iter):
a = numpy.sin(a)
end.record() # end timing
# calculate the run length
end.synchronize()
sec5 = start.time_till(end)*1e-3
print ("CPU time and first three results:")
print ("%fs, %s" % (sec5, str(a[:3])))
results.append([n_iter,sec1,sec2,sec3,sec4,sec5])
スポンサーリンク
pycuda圧勝¶
import matplotlib.pyplot as plt
import numpy as np
results = np.array(results)
legends = []
nH = results[:5, 0:1]
rows = results[:5,1:6]
plt.semilogx(nH,rows, 'o-')
legends += ['' + s for s in ['SourceModule','Elementwise',\
'Elementwise Python looping','GPUArray','CPU']]
plt.rcParams['figure.figsize'] = 18, 10
plt.rcParams["font.size"] = "20"
plt.ylabel('Seconds')
plt.xlabel('Value of n_iter')
plt.legend(legends);
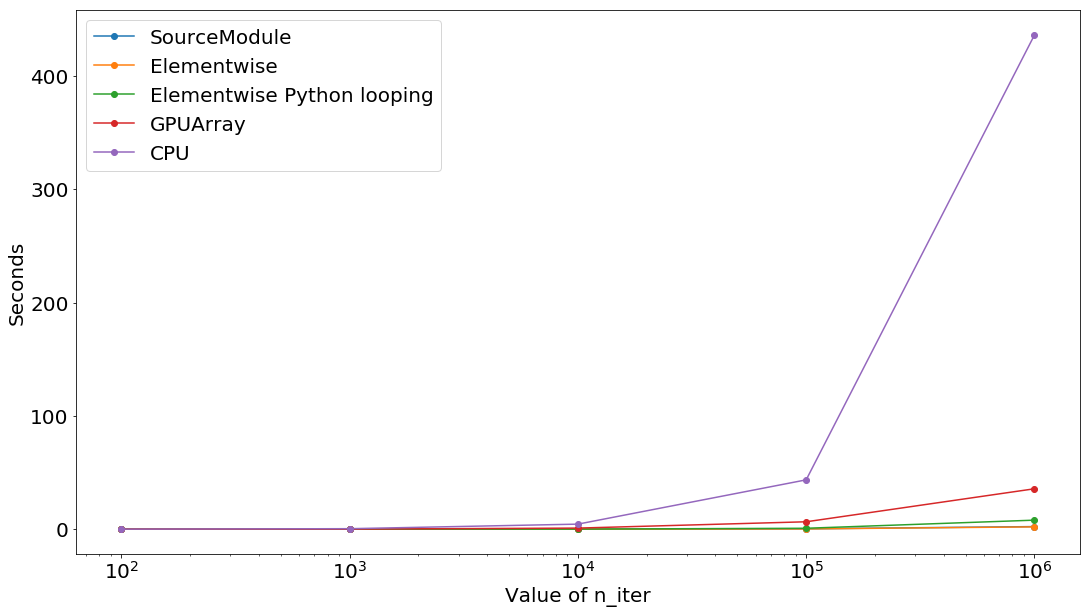
ループ数が100万回だと、pycudaのElementwiseとCPUの差が211.7倍に拡大する。ただ、意外だったのは、ElementwiseとElementwise Python loopingの差が3.87倍しかなかったことだ。ElementwiseとGPUArrayの差は17.3倍で、cumath.sinとnumpy.sinの差は12.2倍だった。
スポンサーリンク